快速入门用户指南
概述
Slurm 是一个开源的、容错的、高度可扩展的集群管理和作业调度系统,适用于大规模和小规模的 Linux 集群。Slurm 在运行时不需要内核修改,并且相对自给自足。作为集群工作负载管理器,Slurm 有三个关键功能。首先,它为用户分配独占和/或非独占的资源(计算节点)访问权限,以便他们在一段时间内进行工作。其次,它提供了一个框架,用于在分配的节点集上启动、执行和监控工作(通常是并行作业)。最后,它通过管理待处理工作的队列来调解资源的争用。
架构
如图 1 所示,Slurm 由在每个计算节点上运行的 slurmd 守护进程和在管理节点上运行的中央 slurmctld 守护进程组成(可选的故障转移双胞胎)。slurmd 守护进程提供容错的分层通信。用户命令包括:sacct、sacctmgr、salloc、sattach、sbatch、sbcast、scancel、scontrol、scrontab、sdiag、sh5util、sinfo、sprio、squeue、sreport、srun、sshare、sstat、strigger 和 sview。所有命令可以在集群的任何地方运行。
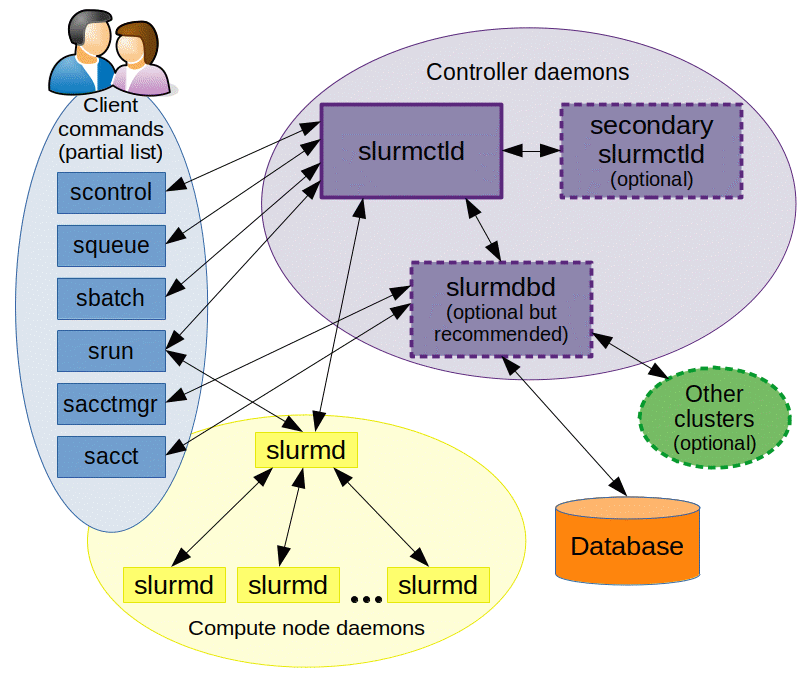
图 1. Slurm 组件
这些 Slurm 守护进程管理的实体,如图 2 所示,包括 节点,Slurm 中的计算资源,分区,将节点分组为逻辑(可能重叠)集合,作业,或分配给用户的资源分配,指定时间段内的 作业步骤,即作业中的一组(可能并行)任务。分区可以视为作业队列,每个队列都有各种约束,例如作业大小限制、作业时间限制、允许使用的用户等。优先级排序的作业在分区内分配节点,直到该分区内的资源(节点、处理器、内存等)耗尽。一旦作业被分配了一组节点,用户就可以以任何配置在分配内启动并行工作,形式为作业步骤。例如,可以启动一个使用分配给作业的所有节点的单一作业步骤,或者多个作业步骤可以独立使用分配的一部分。
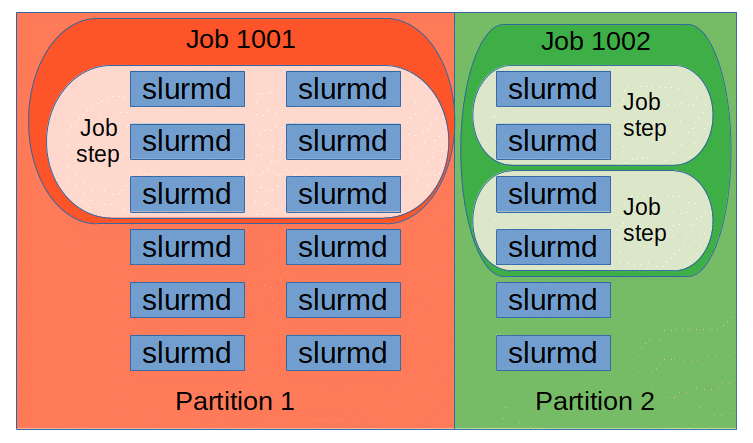
图 2. Slurm 实体
命令
所有 Slurm 守护进程、命令和 API 函数都有手册页。命令选项 --help 也提供了选项的简要摘要。请注意,命令选项都是区分大小写的。
sacct 用于报告有关活动或已完成作业的作业或作业步骤的会计信息。
salloc 用于实时分配作业的资源。通常用于分配资源并启动一个 shell。然后使用该 shell 执行 srun 命令以启动并行任务。
sattach 用于将标准输入、输出和错误以及信号功能附加到当前正在运行的作业或作业步骤。可以多次附加和分离作业。
sbatch 用于提交作业脚本以供后续执行。脚本通常包含一个或多个 srun 命令以启动并行任务。
sbcast 用于将文件从本地磁盘传输到分配给作业的节点上的本地磁盘。这可以有效地利用无磁盘计算节点或提供相对于共享文件系统的更好性能。
scancel 用于取消待处理或正在运行的作业或作业步骤。它还可以用于向与正在运行的作业或作业步骤相关的所有进程发送任意信号。
scontrol 是用于查看和/或修改 Slurm 状态的管理工具。请注意,许多 scontrol 命令只能以 root 用户身份执行。
sinfo 报告 Slurm 管理的分区和节点的状态。它具有多种过滤、排序和格式化选项。
sprio 用于显示影响作业优先级的组件的详细视图。
squeue 报告作业或作业步骤的状态。它具有多种过滤、排序和格式化选项。默认情况下,它按优先级顺序报告正在运行的作业,然后是待处理的作业。
srun 用于提交作业以供执行或实时启动作业步骤。srun 有多种选项来指定资源要求,包括:最小和最大节点数、处理器数、要使用或不使用的特定节点,以及特定节点特性(例如内存、磁盘空间、某些所需功能等)。作业可以包含多个作业步骤,在作业的节点分配内顺序或并行执行。
sshare 显示有关集群中公平共享使用的详细信息。请注意,这仅在使用优先级/多因素插件时有效。
sstat 用于获取有关正在运行的作业或作业步骤所使用的资源的信息。
strigger 用于设置、获取或查看事件触发器。事件触发器包括节点故障或作业接近其时间限制等。
sview 是一个图形用户界面,用于获取和更新 Slurm 管理的作业、分区和节点的状态信息。
示例
首先,我们确定系统上存在的分区、它们包含的节点以及一般系统状态。此信息由 sinfo 命令提供。在下面的示例中,我们发现有两个分区:debug 和 batch。* 紧随名称 debug 表示这是提交作业的默认分区。我们看到这两个分区都处于 UP 状态。一些配置可能包括较大作业的分区,这些分区在周末或晚上处于 DOWN 状态。有关每个分区的信息可能会分布在多行中,以便识别不同状态的节点。在这种情况下,两个节点 adev[1-2] 处于 down 状态。* 紧随状态 down 表示节点没有响应。请注意使用简洁的表达式来指定节点名称,使用公共前缀 adev 和识别的数字范围或特定数字。这种格式允许轻松管理非常大的集群。sinfo 命令具有许多选项,可以轻松以您喜欢的格式查看感兴趣的信息。有关更多信息,请参见手册页。
adev0: sinfo PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up 30:00 2 down* adev[1-2] debug* up 30:00 3 idle adev[3-5] batch up 30:00 3 down* adev[6,13,15] batch up 30:00 3 alloc adev[7-8,14] batch up 30:00 4 idle adev[9-12]
接下来,我们使用 squeue 命令确定系统上存在的作业。ST 字段是作业状态。两个作业处于运行状态(R 是 Running 的缩写),而一个作业处于待处理状态(PD 是 Pending 的缩写)。TIME 字段显示作业运行的时间,格式为 天-小时:分钟:秒。NODELIST(REASON) 字段指示作业正在运行的位置或其仍处于待处理状态的原因。待处理作业的典型原因是 Resources(等待资源可用)和 Priority(排队在更高优先级作业后面)。squeue 命令具有许多选项,可以轻松以您喜欢的格式查看感兴趣的信息。有关更多信息,请参见手册页。
adev0: squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 65646 batch chem mike R 24:19 2 adev[7-8] 65647 batch bio joan R 0:09 1 adev14 65648 batch math phil PD 0:00 6 (Resources)
scontrol 命令可用于报告有关节点、分区、作业、作业步骤和配置的更详细信息。系统管理员还可以使用它进行配置更改。下面显示了几个示例。有关更多信息,请参见手册页。
adev0: scontrol show partition PartitionName=debug TotalNodes=5 TotalCPUs=40 RootOnly=NO Default=YES OverSubscribe=FORCE:4 PriorityTier=1 State=UP MaxTime=00:30:00 Hidden=NO MinNodes=1 MaxNodes=26 DisableRootJobs=NO AllowGroups=ALL Nodes=adev[1-5] NodeIndices=0-4 PartitionName=batch TotalNodes=10 TotalCPUs=80 RootOnly=NO Default=NO OverSubscribe=FORCE:4 PriorityTier=1 State=UP MaxTime=16:00:00 Hidden=NO MinNodes=1 MaxNodes=26 DisableRootJobs=NO AllowGroups=ALL Nodes=adev[6-15] NodeIndices=5-14 adev0: scontrol show node adev1 NodeName=adev1 State=DOWN* CPUs=8 AllocCPUs=0 RealMemory=4000 TmpDisk=0 Sockets=2 Cores=4 Threads=1 Weight=1 Features=intel Reason=Not responding [slurm@06/02-14:01:24] 65648 batch math phil PD 0:00 6 (Resources) adev0: scontrol show job JobId=65672 UserId=phil(5136) GroupId=phil(5136) Name=math Priority=4294901603 Partition=batch BatchFlag=1 AllocNode:Sid=adev0:16726 TimeLimit=00:10:00 ExitCode=0:0 StartTime=06/02-15:27:11 EndTime=06/02-15:37:11 JobState=PENDING NodeList=(null) NodeListIndices= NumCPUs=24 ReqNodes=1 ReqS:C:T=1-65535:1-65535:1-65535 OverSubscribe=1 Contiguous=0 CPUs/task=0 Licenses=(null) MinCPUs=1 MinSockets=1 MinCores=1 MinThreads=1 MinMemory=0 MinTmpDisk=0 Features=(null) Dependency=(null) Account=(null) Requeue=1 Reason=None Network=(null) ReqNodeList=(null) ReqNodeListIndices= ExcNodeList=(null) ExcNodeListIndices= SubmitTime=06/02-15:27:11 SuspendTime=None PreSusTime=0 Command=/home/phil/math WorkDir=/home/phil
可以使用 srun 命令在单个命令行中创建资源分配并启动作业步骤的任务。根据使用的 MPI 实现,MPI 作业也可以以这种方式启动。有关更具体的 MPI 信息,请参见 MPI 部分。在此示例中,我们在三个节点上执行 /bin/hostname(-N3),并在输出中包含任务编号(-l)。将使用默认分区。默认情况下,每个节点将使用一个任务。请注意,srun 命令有许多选项可用于控制分配的资源以及任务如何在这些资源之间分配。
adev0: srun -N3 -l /bin/hostname 0: adev3 1: adev4 2: adev5
此示例的变体在四个任务中执行 /bin/hostname(-n4)。默认情况下,每个任务将使用一个处理器(请注意,我们没有指定节点数)。
adev0: srun -n4 -l /bin/hostname 0: adev3 1: adev3 2: adev3 3: adev3
一种常见的操作模式是提交脚本以供后续执行。在此示例中,脚本名称为 my.script,我们明确使用节点 adev9 和 adev10(-w "adev[9-10]",请注意使用节点范围表达式)。我们还明确说明后续作业步骤将每个启动四个任务,这将确保我们的分配至少包含四个处理器(每个任务一个处理器)。输出将出现在文件 my.stdout 中("-o my.stdout")。此脚本包含嵌入在其中的作业时间限制。可以通过在脚本开头(在要执行的任何命令之前)使用 "#SBATCH" 前缀后跟选项来提供其他选项。命令行中提供的选项将覆盖脚本中指定的任何选项。请注意,my.script 包含在分配的第一个节点上执行的命令 /bin/hostname,以及使用 srun 命令启动的两个作业步骤,并按顺序执行。
adev0: cat my.script #!/bin/sh #SBATCH --time=1 /bin/hostname srun -l /bin/hostname srun -l /bin/pwd adev0: sbatch -n4 -w "adev[9-10]" -o my.stdout my.script sbatch: 提交批处理作业 469 adev0: cat my.stdout adev9 0: adev9 1: adev9 2: adev10 3: adev10 0: /home/jette 1: /home/jette 2: /home/jette 3: /home/jette
最后一种操作模式是创建资源分配并在该分配内启动作业步骤。salloc 命令用于创建资源分配,并通常在该分配内启动一个 shell。通常会在该分配内执行一个或多个作业步骤,使用 srun 命令启动任务(根据使用的 MPI 类型,启动机制可能不同,详见下面的 MPI 详细信息)。最后,使用 exit 命令终止由 salloc 创建的 shell。Slurm 不会自动将可执行文件或数据文件迁移到分配给作业的节点。文件必须存在于本地磁盘或某个全局文件系统中(例如 NFS 或 Lustre)。我们提供了工具 sbcast,用于通过 Slurm 的分层通信将文件传输到分配节点的本地存储。在此示例中,我们使用 sbcast 将可执行程序 a.out 传输到分配节点的本地存储 /tmp/joe.a.out。执行程序后,我们将其从本地存储中删除。
tux0: salloc -N1024 bash $ sbcast a.out /tmp/joe.a.out 授予作业分配 471 $ srun /tmp/joe.a.out 结果是 3.14159 $ srun rm /tmp/joe.a.out $ exit salloc: 放弃作业分配 471
在此示例中,我们提交一个批处理作业,获取其状态并取消它。
adev0: sbatch test srun: jobid 473 提交 adev0: squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 473 batch test jill R 00:00 1 adev9 adev0: scancel 473 adev0: squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
最佳实践,大量作业计数
考虑将相关工作放入一个包含多个作业步骤的单个 Slurm 作业中,以提高性能和管理的便利性。每个 Slurm 作业可以包含多个作业步骤,Slurm 管理作业步骤的开销远低于单个作业。
作业数组 是管理具有相同资源需求的批处理作业集合的有效机制。大多数 Slurm 命令可以将作业数组管理为单个元素(任务)或作为单个实体(例如,在单个命令中删除整个作业数组)。
MPI
MPI 的使用取决于所使用的 MPI 类型。这些不同的 MPI 实现使用三种根本不同的操作模式。
- Slurm 直接启动任务并通过 PMI2 或 PMIx API 执行通信初始化。(大多数现代 MPI 实现支持。)
- Slurm 为作业创建资源分配,然后 mpirun 使用 Slurm 的基础设施启动任务(旧版本的 OpenMPI)。
- Slurm 为作业创建资源分配,然后 mpirun 使用除 Slurm 之外的某种机制启动任务,例如 SSH 或 RSH。这些任务在 Slurm 的监控或控制之外启动。应配置 Slurm 的 epilog 以在作业的分配被放弃时清除这些任务。强烈建议使用 pam_slurm_adopt。
下面提供了使用几种不同类型的 MPI 与 Slurm 的说明链接。
最后修改于 2021 年 6 月 29 日