对多核/多线程架构的支持
目录
定义
- 主板
- 也称为母板。
- LDom
- 局部性域或 NUMA 域。可能等同于主板或插槽。
- 插槽/核心/线程
- 图 1 说明了插槽、核心和线程的概念,如 Slurm 的多核/多线程支持文档中所定义。
- CPU
- 根据系统配置,这可以是核心或线程。
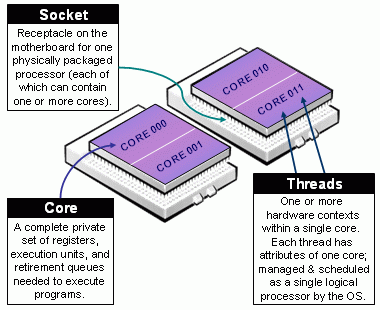
图 1:插槽、核心和线程的定义
- 亲和性
- 绑定到特定逻辑处理器的状态。
- 亲和性掩码
- 一个位掩码,其中索引对应于逻辑处理器。 最低有效位对应于系统上的第一个逻辑处理器编号,而最高有效位对应于系统上的最后一个逻辑处理器编号。 在给定位置的 '1' 表示进程可以在相关的逻辑处理器上运行。
- Fat Masks
- 具有多个位设置的亲和性掩码,允许进程在多个逻辑处理器上运行。
srun 标志概述
定义了许多标志,以便用户能够更好地利用此架构,通过明确指定其应用程序所需的插槽、核心和线程数量。表 1 总结了这些选项。
| 低级(显式绑定) | |
| --cpu-bind=... | 显式进程亲和性绑定和控制选项 |
| 高级(自动掩码生成) | |
| --sockets-per-node=S | 分配给作业的节点中的插槽数量(最小) |
| --cores-per-socket=C | 分配给作业的插槽中的核心数量(最小) |
| --threads-per-core=T | 分配给作业的核心中的线程最小数量。在任务布局中,使用指定的每核心最大线程数。 |
| -B S[:C[:T]] | --sockets-per-node、--cores-per_cpu、--threads-per_core 的组合快捷选项 |
| 任务分配选项 | |
| -m / --distribution | 分配方式:任意 | 块 | 循环 | plane=x | [block|cyclic]:[block|cyclic|fcyclic] |
| 内存作为可消耗资源 | |
| --mem=mem | 作业所需的每个节点的实际内存量。 |
| --mem-per-cpu=mem | 作业所需的每个分配 CPU 的实际内存量。 |
| 任务调用控制 | |
| --cpus-per-task=CPUs | 每个任务所需的 CPU 数量 | --ntasks-per-node=ntasks | 每个节点上调用的任务数量 | --ntasks-per-socket=ntasks | 每个插槽上调用的任务数量 | --ntasks-per-core=ntasks | 每个核心上调用的任务数量 | --overcommit | 允许每个 CPU 超过一个任务 |
| 应用提示 | |
| --hint=compute_bound | 使用每个插槽中的所有核心 | --hint=memory_bound | 每个插槽中仅使用一个核心 | --hint=[no]multithread | [不]使用具有内核多线程的额外线程 |
| 保留给系统使用的资源 | |
| --core-spec=cores | 为系统使用保留的核心数量 | --thread-spec=threads | 为系统使用保留的线程数量 |
重要的是要注意,许多这些标志只有在进程与特定 CPU 具有某种亲和性时才有意义(可选地)内存。 不一致的选项通常会导致错误。 任务亲和性通过 slurm.conf 文件中的 TaskPlugin 参数进行配置。 根据系统架构和可用软件,TaskPlugin 有几种选项,除了 "task/none" 之外的任何选项都将任务绑定到 CPU。 如果通过configurator.html 生成 slurm.conf,请参见 "任务启动" 部分。
低级 --cpu-bind=... - 显式绑定接口
以下 srun 标志提供了一个低级核心绑定接口:
--cpu-bind= 绑定任务到 CPU
q[uiet] 在任务运行之前静默绑定(默认)
v[erbose] 在任务运行之前详细报告绑定
no[ne] 不将任务绑定到 CPU(默认)
rank 按任务排名绑定
map_cpu:<list> 为每个任务指定 CPU ID 绑定
其中 <list> 是
<cpuid1>,<cpuid2>,...<cpuidN>
mask_cpu:<list> 为每个任务指定 CPU ID 绑定掩码
其中 <list> 是
<mask1>,<mask2>,...<maskN>
rank_ldom 按排名将任务绑定到 NUMA
局部性域中的 CPU
map_ldom:<list> 为每个任务指定 NUMA 局部性域 ID
其中 <list> 是
<ldom1>,<ldom2>,...<ldomN>
rank_ldom 按排名将任务绑定到 NUMA
局部性域中的 CPU,其中 <list> 是
<ldom1>,<ldom2>,...<ldomN>
mask_ldom:<list> 为每个任务指定 NUMA 局部性域 ID 掩码
其中 <list> 是
<ldom1>,<ldom2>,...<ldomN>
ldoms 自动生成的掩码绑定到 NUMA 局部性
域
sockets 自动生成的掩码绑定到插槽
cores 自动生成的掩码绑定到核心
threads 自动生成的掩码绑定到线程
help 显示此帮助信息
亲和性可以设置为特定的逻辑处理器(插槽、核心、线程)或比逻辑处理器的最低级别更粗糙的粒度(核心或线程)。 在后者的情况下,允许进程在特定插槽或核心内利用多个处理器。
示例:
- srun -n 8 -N 4 --cpu-bind=mask_cpu:0x1,0x4 a.out
- srun -n 8 -N 4 --cpu-bind=mask_cpu:0x3,0xD a.out
另请参见 'srun --cpu-bind=help' 和 'man srun'
高级 -B S[:C[:T]] - 自动掩码生成接口
我们已更新节点选择基础设施,允许以更细粒度选择逻辑处理器。用户可以请求特定数量的节点、插槽、核心和线程:
-B, --extra-node-info=S[:C[:T]] 扩展为:
--sockets-per-node=S 每个节点分配的插槽数量
--cores-per-socket=C 每个插槽分配的核心数量
--threads-per-core=T 每个核心分配的线程数量
每个字段可以是 'min' 或通配符 '*'
请求的总 CPU = (节点) x (S x C x T)
示例:
- srun -n 8 -N 4 -B 2:1 a.out
- srun -n 8 -N 4 -B 2 a.out
注意:将上述与之前相应的 --cpu-bind=... 示例进行比较 - srun -n 16 -N 4 a.out
- srun -n 16 -N 4 -B 2:2:1 a.out
- srun -n 16 -N 4 -B 2:2:1 a.out
或 - srun -n 16 -N 4 --sockets-per-node=2 --cores-per-socket=2 --threads-per-core=1 a.out
- srun -n 16 -N 2-4 -B '1:*:1' a.out
- srun -n 16 -N 4-2 -B '2:*:1' a.out
- srun -n 16 -N 4-4 -B '1:1' a.out
注意:
- 在命令行中添加 --cpu-bind=no 将导致进程不绑定到逻辑处理器。
- 在命令行中添加 --cpu-bind=verbose(或将 CPU_BIND 环境变量设置为 "verbose")将导致每个任务报告正在使用的亲和性掩码
- 当使用 -B 时,绑定默认开启。在多核/多线程系统上的默认绑定相当于 -B 选项中列举的资源级别。
另请参见 'srun --help' 和 'man srun'
任务分配选项:对 -m / --distribution 的扩展
-m / --distribution 选项用于在节点之间分配进程,已扩展为描述逻辑处理器最低级别内的分配。
可用的分配包括:
任意 | 块 | 循环 | plane=x | [block|cyclic]:[block|cyclic|fcyclic]
平面分配 (plane=x) 导致块:循环的分配,块大小等于 x。 在以下内容中,我们使用 "逻辑处理器的最低级别" 来描述插槽、核心或线程,具体取决于架构。 该分配将集群划分为平面(包括每个节点上最低级别逻辑处理器的数量),然后首先在每个平面内调度,然后跨平面调度。
对于二维分配([block|cyclic]:[block|cyclic|fcyclic]),第二个分配(在 ":" 之后)允许用户为节点内的进程指定分配方法,并适用于最低级别的逻辑处理器(插槽、核心或线程,具体取决于架构)。 当任务需要多个 CPU 时,cyclic 将作为一组分配所有这些 CPU(即如果可能的话在同一个插槽内),而 fcyclic 将以循环方式分配每个 CPU 跨插槽。
当使用高级标志时,绑定会自动启用,只要任务/亲和性插件已启用。要在作业级别禁用绑定,请使用 --cpu-bind=no。
分配标志可以与其他开关组合:
- srun -n 16 -N 4 -B '2:*:1' -m block:cyclic --cpu-bind=socket a.out
- srun -n 16 -N 4 -B '2:*:1' -m plane=2 --cpu-bind=core a.out
- srun -n 16 -N 4 -B '2:*:1' -m plane=2 a.out
在多核/多线程系统上的默认分配相当于 -m block:cyclic 和 --cpu-bind=thread。
另请参见 'srun --help'
内存作为可消耗资源
--mem 标志指定作业每个节点所需的最大内存量(以 MB 为单位)。此标志用于支持内存作为可消耗资源的分配策略。
--mem=MB 每个节点所需的最大实际内存量
由作业要求。
此标志允许调度程序在特定节点上共同分配作业,前提是它们的总内存需求不超过节点上的总内存量。
为了将内存用作可消耗资源,必须首先在 slurm.conf 中启用 select/cons_tres 插件:
SelectType=select/cons_tres # 启用可消耗资源 SelectTypeParameters=CR_Memory # 内存作为可消耗资源
将内存作为可消耗资源通常与 CPU、插槽或核心可消耗资源结合使用,使用 SelectTypeParameters 值:CR_CPU_Memory、CR_Socket_Memory 或 CR_Core_Memory
如果通过 configurator.html 生成 slurm.conf,请参见 "资源选择" 部分。
另请参见 'srun --help' 和 'man srun'
任务调用作为逻辑处理器的函数
--ntasks-per-{node,socket,core}=ntasks 标志允许用户请求在每个节点、插槽或核心上调用不超过 ntasks 的任务。 这类似于使用 --cpus-per-task=ncpus,但不需要知道每个节点上实际的 CPU 数量。在某些情况下,能够请求在每个节点、插槽或核心上调用不超过特定数量的 ntasks 更为方便。这包括提交一个应用程序,其中只有一个 "任务/排名" 应分配给每个节点,同时允许作业利用节点中存在的所有并行性,或者将单个设置/清理/监控作业提交到预先存在的分配的每个节点,作为更大作业脚本中的一步。 现在可以通过以下标志指定:
--ntasks-per-node=n 每个节点上调用的任务数量 --ntasks-per-socket=n 每个插槽上调用的任务数量 --ntasks-per-core=n 每个核心上调用的任务数量
例如,给定一个包含两个插槽的节点的集群,每个插槽包含两个核心,以下命令说明了这些标志的行为:
% srun -n 4 hostname hydra12 hydra12 hydra12 hydra12 % srun -n 4 --ntasks-per-node=1 hostname hydra12 hydra13 hydra14 hydra15 % srun -n 4 --ntasks-per-node=2 hostname hydra12 hydra12 hydra13 hydra13 % srun -n 4 --ntasks-per-socket=1 hostname hydra12 hydra12 hydra13 hydra13 % srun -n 4 --ntasks-per-core=1 hostname hydra12 hydra12 hydra12 hydra12
另请参见 'srun --help' 和 'man srun'
应用提示
不同的应用程序将具有不同级别的资源需求。一些应用程序往往是计算密集型的,但几乎不需要进程间通信。一些应用程序将是内存绑定的,在耗尽计算能力之前饱和处理器的内存带宽。其他应用程序将高度通信密集,导致进程在等待来自其他进程的消息时阻塞。具有这些不同属性的应用程序在多核系统上运行良好,只要映射正确。
对于计算密集型应用程序,通常会使用多核系统中的所有核心。对于内存绑定的应用程序,仅在每个插槽中使用单个核心将导致每个核心的内存带宽最高。对于通信密集型应用程序,使用内核内多线程(例如超线程、SMT 或 TMT)也可能提高性能。 以下命令行标志可用于将这些类型的应用提示传达给 Slurm 多核支持:
--hint= 根据应用提示绑定任务
compute_bound 使用每个插槽中的所有核心
memory_bound 每个插槽中仅使用一个核心
[no]multithread [不]使用具有内核多线程的额外线程
help 显示此帮助信息
例如,给定一个包含两个插槽的节点的集群,每个插槽包含两个核心,以下命令说明了这些标志的行为。在详细的 --cpu-bind 输出中,任务被描述为 'hostname, task Global_ID Local_ID [PID]':
% srun -n 4 --hint=compute_bound --cpu-bind=verbose sleep 1 cpu-bind=MASK - hydra12, task 0 0 [15425]: mask 0x1 set cpu-bind=MASK - hydra12, task 1 1 [15426]: mask 0x4 set cpu-bind=MASK - hydra12, task 2 2 [15427]: mask 0x2 set cpu-bind=MASK - hydra12, task 3 3 [15428]: mask 0x8 set % srun -n 4 --hint=memory_bound --cpu-bind=verbose sleep 1 cpu-bind=MASK - hydra12, task 0 0 [15550]: mask 0x1 set cpu-bind=MASK - hydra12, task 1 1 [15551]: mask 0x4 set cpu-bind=MASK - hydra13, task 2 0 [14974]: mask 0x1 set cpu-bind=MASK - hydra13, task 3 1 [14975]: mask 0x4 set
另请参见 'srun --hint=help' 和 'man srun'
高层 srun 标志背后的动机
允许用户使用更高层次的 srun 标志而不是 --cpu-bind 的动机在于后者可能难以使用。提出的高层标志比 --cpu-bind 更易于使用,因为:
- 使用高层标志时,亲和性掩码生成会自动发生。
- --cpu-bind 标志的长度和复杂性与 -B 和 --distribution 标志组合的长度相比,使高层标志更易于使用。
如下面的示例所示,使用高层标志指定不同布局要简单得多,因为用户不必重新计算掩码或 CPU ID。这种方法比重新排列掩码或映射简单得多。
给定一个 32 进程的作业和一个四节点、双插槽、双核心的集群,我们希望在四个节点之间使用块分配,然后在节点内跨物理处理器使用循环分配。下面我们展示如何使用 1) 高层标志和 2) --cpubind 获得所需的布局。
高层标志
使用 Slurm 的高层标志,用户可以通过以下任一提交获得上述布局,因为 --distribution=block:cyclic 是默认的分配方法。
$ srun -n 32 -N 4 -B 4:2 --distribution=block:cyclic a.out或
$ srun -n 32 -N 4 -B 4:2 a.out
核心显示为 c0 和 c1,处理器显示为 p0 到 p3。结果任务 ID 为:
|
|
任务 ID 的计算和分配对用户是透明的。用户不必担心核心编号(第节 将进程固定到核心)或设置任何 CPU 亲和性。默认情况下,使用多核支持标志时将设置 CPU 亲和性。
低级标志 --cpu-bind
使用 Slurm 的 --cpu-bind 标志,用户必须计算 CPU ID 或掩码,并确保他们理解系统上的核心编号。当所有节点的核心编号不同时,会出现另一个问题。 --cpu-bind 选项仅允许用户为所有节点指定单个掩码。使用 Slurm 高层标志消除了这一限制,因为 Slurm 将为每个请求的节点正确生成适当的掩码。
在一个四个双插槽双核心节点集群中,核心块编号
核心显示为 c0 和 c1,处理器显示为 p0 到 p3。块编号中节点内的 CPU ID 为: (此信息可从系统上的 /proc/cpuinfo 文件中获得)
|
|
导致用户需要计算的处理器/核心和任务 ID 的以下映射:
|
|
|
|
上述映射和任务 ID 可以转换为以下命令:
$ srun -n 32 -N 4 --cpu-bind=mask_cpu:1,4,10,40,2,8,20,80 a.out或
$ srun -n 32 -N 4 --cpu-bind=map_cpu:0,2,4,6,1,3,5,7 a.out
同一集群,但其核心编号为循环而不是块
在一个核心编号为循环的系统中,srun 命令的正确掩码参数看起来像:(这将在具有核心块编号的系统上实现与上述命令相同的布局。)
$ srun -n 32 -N 4 --cpu-bind=map_cpu:0,1,2,3,4,5,6,7 a.out
在具有循环核心编号的系统上使用块 map_cpu
如果用户在指定 map_cpu 列表之前未检查其系统的核心编号,从而未意识到系统具有循环核心编号而不是块编号,则他们将无法获得预期的布局。例如,如果他们决定重用上述命令:
$ srun -n 32 -N 4 --cpu-bind=map_cpu:0,2,4,6,1,3,5,7 a.out
他们会得到以下意外的任务 ID 布局:
|
|
因为在循环编号中节点内的处理器 ID 为:
|
|
重要的结论是,使用 --cpu-bind 标志并不简单,并且假设用户是专家。
对 sinfo/squeue/scontrol 的扩展
还对其他 Slurm 工具进行了若干扩展,以便更轻松地与多核/多线程系统进行交互。
sinfo
sinfo 节点列表的长版本 (-l) 已扩展为显示每个节点的插槽、核心和线程。例如:
% sinfo -N NODELIST NODES PARTITION STATE hydra[12-15] 4 parts* idle % sinfo -lN Thu Sep 14 17:47:13 2006 NODELIST NODES PARTITION STATE CPUS S:C:T MEMORY TMP_DISK WEIGHT FEATURES REASON hydra[12-15] 4 parts* idle 8+ 2+:4+:1+ 2007 41447 1 (null) none % sinfo -lNe Thu Sep 14 17:47:18 2006 NODELIST NODES PARTITION STATE CPUS S:C:T MEMORY TMP_DISK WEIGHT FEATURES REASON hydra[12-14] 3 parts* idle 8 2:4:1 2007 41447 1 (null) none hydra15 1 parts* idle 64 8:4:2 2007 41447 1 (null) none
对于用户指定的输出格式 (-o/--format) 和排序 (-S/--sort),以下标识符可用:
%X 每个节点的插槽数量 %Y 每个插槽的核心数量 %Z 每个核心的线程数量 %z 扩展处理器信息:每个节点的插槽、核心、线程数量(S:C:T)
例如:
% sinfo -o '%9P %4c %8z %8X %8Y %8Z' PARTITION CPUS S:C:T SOCKETS CORES THREADS parts* 4 2:2:1 2 2 1
另请参见 'sinfo --help' 和 'man sinfo'
squeue
对于用户指定的输出格式 (-o/--format) 和排序 (-S/--sort),以下标识符可用:
%m 作业请求的内存大小(以 MB 为单位) %H 每个节点请求的插槽数量 %I 每个插槽请求的核心数量 %J 每个核心请求的线程数量 %z 扩展处理器信息:每个节点请求的插槽、核心、线程数量(S:C:T)
以下是运行 7 个副本后的示例 squeue 输出:
- % srun -n 4 -B 2:2:1 --mem=1024 sleep 100 &
% squeue -o '%.5i %.2t %.4M %.5D %7H %6I %7J %6z %R' JOBID ST TIME NODES SOCKETS CORES THREADS S:C:T NODELIST(REASON) 17 PD 0:00 1 2 2 1 2:2:1 (资源) 18 PD 0:00 1 2 2 1 2:2:1 (资源) 19 PD 0:00 1 2 2 1 2:2:1 (资源) 13 R 1:27 1 2 2 1 2:2:1 hydra12 14 R 1:26 1 2 2 1 2:2:1 hydra13 15 R 1:26 1 2 2 1 2:2:1 hydra14 16 R 1:26 1 2 2 1 2:2:1 hydra15
squeue 命令还可以显示作业的内存大小,例如:
% sbatch --mem=123 tmp 提交批处理作业 24 $ squeue -o "%.5i %.2t %.4M %.5D %m" JOBID ST TIME NODES MIN_MEMORY 24 R 0:05 1 123
另请参见 'squeue --help' 和 'man squeue'
scontrol
可以使用 scontrol 调整以下作业设置:
请求的分配: ReqSockets=<count> 设置作业所需的插槽数量 ReqCores=<count> 设置作业所需的核心数量 ReqThreads=<count> 设置作业所需的线程数量
例如:
# scontrol update JobID=17 ReqThreads=2 # scontrol update JobID=18 ReqCores=4 # scontrol update JobID=19 ReqSockets=8 % squeue -o '%.5i %.2t %.4M %.5D %9c %7H %6I %8J' JOBID ST TIME NODES MIN_PROCS SOCKETS CORES THREADS 17 PD 0:00 1 1 4 2 1 18 PD 0:00 1 1 8 4 2 19 PD 0:00 1 1 4 2 1 13 R 1:35 1 0 0 0 0 14 R 1:34 1 0 0 0 0 15 R 1:34 1 0 0 0 0 16 R 1:34 1 0 0 0
'scontrol show job' 命令可用于显示每个节点分配的 CPU 数量以及请求和约束中指定的插槽、核心和线程。
% srun -N 2 -B 2:1 sleep 100 & % scontrol show job 20 JobId=20 UserId=(30352) GroupId=users(1051) Name=sleep Priority=4294901749 Partition=parts BatchFlag=0 AllocNode:Sid=hydra16:3892 TimeLimit=UNLIMITED JobState=RUNNING StartTime=09/25-17:17:30 EndTime=NONE NodeList=hydra[12-14] NodeListIndices=0,2,-1 AllocCPUs=1,2,1 NumCPUs=4 ReqNodes=2 ReqS:C:T=2:1:* OverSubscribe=0 Contiguous=0 CPUs/task=0 MinCPUs=0 MinMemory=0 MinTmpDisk=0 Features=(null) Dependency=0 Account=(null) Reason=None Network=(null) ReqNodeList=(null) ReqNodeListIndices=-1 ExcNodeList=(null) ExcNodeListIndices=-1 SubmitTime=09/25-17:17:30 SuspendTime=None PreSusTime=0
另请参见 'scontrol --help' 和 'man scontrol'
slurm.conf 中的配置设置
有几个 slurm.conf 设置可用于控制上述多核功能。
除了下面的描述外,如果通过 configurator.html 生成 slurm.conf,请参见 "任务启动" 和 "资源选择" 部分。
如前所述,为了设置亲和性,必须首先在 slurm.conf 中启用任务/亲和性插件:
TaskPlugin=task/affinity # 启用任务亲和性
此设置是任务启动特定参数的一部分:
# o 定义任务启动特定参数 # # "TaskProlog" : 定义每个任务开始执行之前作为用户执行的程序。 # "TaskEpilog" : 定义每个任务终止后作为用户执行的程序。 # "TaskPlugin" : 定义任务启动插件。这可以用于提供节点内的资源管理(例如,将任务固定到特定处理器)。允许的值为: # "task/affinity" : CPU 亲和性支持 # "task/cgroup" : 使用 Linux cgroup 将任务绑定到资源 # "task/none" : 无任务启动操作,默认值 # # 示例: # # TaskProlog=/usr/local/slurm/etc/task_prolog # 默认值为无 # TaskEpilog=/usr/local/slurm/etc/task_epilog # 默认值为无 # TaskPlugin=task/affinity # 默认值为 task/none
在 slurm.conf 中声明节点硬件配置:
NodeName=dualcore[01-16] CoresPerSocket=2 ThreadsPerCore=1
有关各种节点配置选项的更完整描述,请参见 slurm.conf 手册页。
最后修改于 2023 年 5 月 19 日