使用 HDF5 进行性能分析用户指南
目录
概述
acct_gather_profile/hdf5 插件允许 Slurm 协调收集其在集群上运行的作业的数据,这些数据比其数据库中包含的更详细。数据来自定期采样的各种性能数据,这些数据可以由 Slurm、操作系统或组件软件收集。该插件将记录来自每个来源的数据作为 时间序列,并为每个作业的每个统计信息累积总数。
时间序列是由 acct_gather_energy 插件收集的能量数据,由 acct_gather_interconnect 插件收集的网络接口的 I/O 数据,由 acct_gather_filesystem 插件收集的并行文件系统(如 Lustre)的 I/O 数据,以及由 jobacct_gather 插件收集的任务性能数据,如本地磁盘 I/O、CPU 消耗和内存使用。未来可能会添加来自其他来源的数据。
数据被收集到每个作业的每个分配节点的共享文件系统中的一个文件中,然后合并到一个 HDF5 文件中。选择在共享文件系统上使用单独的文件是因为数据可能非常庞大,因此通过 RPC 将数据传递给 Slurm 控制守护进程的解决方案可能无法扩展到非常大的集群或具有许多分配节点的作业。
管理
共享文件系统
HDF5 配置插件要求所有计算节点上都有一个公共的共享文件系统。在作业运行时,插件会在该文件系统中为作业的每个步骤在每个节点上写入一个文件。当作业结束时,合并过程会启动,节点步骤文件会合并为一个 HDF5 文件。
目录结构的根目录在 acct_gather.conf 文件中的 ProfileHDF5Dir 选项中声明。如果该目录不存在,Slurm 将创建该目录。每个用户将在 ProfileHDF5Dir 中创建自己的目录,其中包含 HDF5 文件。所有目录和文件都是由通常为 root 的 SlurmdUser 创建的。用户特定的目录以及其中的文件都被更改为运行作业的用户,以便他们可以访问这些文件。由于通常是 root 用户创建这些文件/目录,因此根目录压缩的文件系统将不适用于 ProfileHDF5Dir。
每个创建配置文件的用户将在配置文件目录中拥有一个子目录,该子目录仅对该用户具有读/写权限。
配置参数
配置插件在 slurm.conf 文件中启用,并在 acct_gather.conf 文件中进行内部配置。
slurm.conf 参数
- AcctGatherProfileType=acct_gather_profile/hdf5
- 启用 HDF5 插件。
- JobAcctGatherFrequency=<秒数>
- 设置数据类型的采样频率。
acct_gather.conf 参数
这些参数由 HDF5 配置插件直接使用。
- ProfileHDF5Dir=<路径>
- 此参数是共享文件夹的路径,acct_gather_profile 插件将详细数据写入该文件夹,作为 HDF5 文件。假定该目录位于控制器和所有计算节点共享的文件系统上。此参数是必需的。
- ProfileHDF5Default=[选项]
- 要为每个作业提交收集的数据类型的逗号分隔列表。使用此选项时请谨慎。每个作业的每个步骤将在每个节点上创建一个节点步骤文件。它们不会自动合并到作业文件中。(即使是大量小作业的作业文件也会填满文件系统。)此选项旨在用于测试环境,在该环境中,您可能希望分析一系列作业,但不想在启动脚本中添加 --profile 选项。 选项在下面和 acct_gather.conf、srun、salloc 和 sbatch 命令的手册页中进行了描述。
时间序列控制参数
其他插件将时间序列数据添加到 HDF5 集合中。它们通常在 slurm.conf 中的 JobAcctGatherFrequency 参数中指定默认轮询频率。可以使用 --acctg-freq srun 参数覆盖轮询频率。 它们的形式为 task=秒,energy=秒,filesystem=秒,network=秒。
IPMI 能量插件还需要在 acct_gather.conf 文件中设置 EnergyIPMIFrequency 值。这设置了插件采样外部传感器的速率。此值应与 JobAcctGatherFrequency 或 --acctg-freq 中的 energy=秒相同。
请注意,IPMI 和配置采样不是同步的。 配置样本仅取最后可用的 IPMI 样本值。 如果配置能量样本的频率高于 IPMI 样本速率,则 IPMI 值将被重复。如果配置能量样本的频率高于 IPMI 速率,则将丢失 IPMI 值。
还请注意,2013 年时代的 Intel 处理器的最小有效 IPMI(EnergyIPMIFrequency)样本速率为 3 秒。
分析作业
数据收集
在 salloc|sbatch|srun 上的 --profile 选项控制是否收集数据以及收集什么类型的数据。如果未指定 --profile,则不会收集任何数据,除非在 acct_gather.conf 中使用 ProfileHDF5Default 选项。命令行上的 --profile 会覆盖配置文件中指定的任何值。
- --profile=<all|none|[energy[,|task[,|filesystem[,|network]]]]>
- 启用 acct_gather_profile 插件的详细数据收集。详细数据通常是存储在作业的 HDF5 文件中的时间序列。
-
- 所有
- 收集所有数据类型。(不能与其他值组合。)
- 无
- 不收集数据类型。这是默认值。(不能与其他值组合。)
- 能量
- 收集能量数据。
- 文件系统
- 收集文件系统数据。目前仅支持 Lustre 文件系统。
- 网络
- 收集网络(InfiniBand)数据。
- 任务
- 收集任务(I/O、内存等)数据。
数据合并
节点步骤文件通过使用 sh5util 合并为一个 HDF5 文件。
如果作业是通过 sbatch 启动的,则命令行可以添加到正常的启动脚本中,例如:
sbatch -n1 -d$SLURM_JOB_ID --wrap="sh5util -j $SLURM_JOB_ID"
数据提取
sh5util 程序也可以用于从 HDF5 文件中提取特定数据,并以 逗号分隔值 (csv) 形式写入,以便导入到其他分析工具中,如电子表格。
HDF5
HDF5 是一个众所周知的结构化数据集,允许将异构但相关的数据存储在一个文件中。 (即能量统计、网络 I/O、任务数据等的部分。) 其内部结构类似于一个文件系统,其中 组 类似于 目录,而 数据集 类似于 文件。它还允许将 属性 附加到组上,以存储应用程序定义的属性。
有一些商品程序,特别是 HDFView,用于查看和操作这些文件。
下面是 HDFView 展开作业树并显示特定任务属性的屏幕截图。
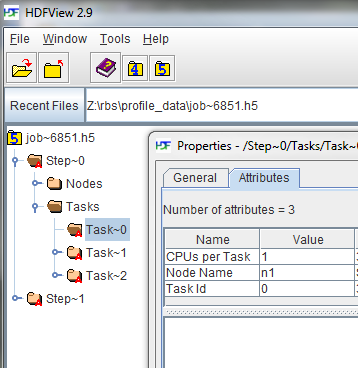
数据结构
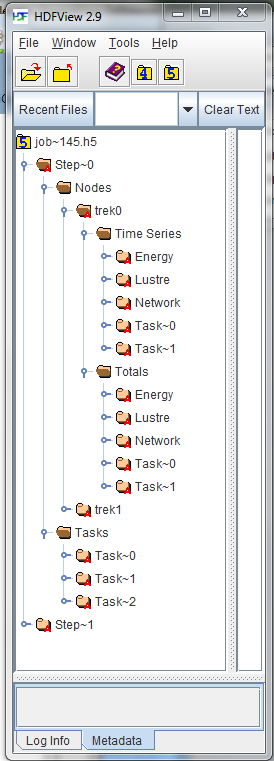 |
在作业文件中,每个作业的每个 步骤 将有一个组。 在每个步骤中,将有一个节点组和一个任务组。
|
能量数据
AcctGatherEnergyType=acct_gather_energy/ipmi
在 slurm.conf 中是收集能量数据所必需的。 适当地在 slurm.conf 中的 JobAcctGatherFrequency 或命令行中的 --acctg-freq 中设置 energy=freq。 同时适当地在 acct_gather.conf 中设置 EnergyIPMIFrequency。
能量时间序列中的每个数据样本包含以下数据项。
- 日期时间
- 数据样本采集时的时间。这可以用于将活动与其他来源(如日志)关联起来。
- 时间
- 自步骤开始以来的经过时间。
- 功率
- 在该时间段内的功耗。
- CPU 频率
- 采样时的 CPU 频率(以千赫兹为单位)。
文件系统数据
AcctGatherFilesystemType=acct_gather_filesystem/lustre
在 slurm.conf 中是收集任务数据所必需的。 适当地在 slurm.conf 中的 JobAcctGatherFrequency 或命令行中的 --acctg-freq 中设置 Filesystem=freq。
文件系统时间序列中的每个数据样本包含以下数据项。
- 日期时间
- 数据样本采集时的时间。这可以用于将活动与其他来源(如日志)关联起来。
- 时间
- 自步骤开始以来的经过时间。
- 读取次数
- 读取操作的数量。
- 读取的兆字节数
- 读取的兆字节数。
- 写入次数
- 写入操作的数量。
- 写入的兆字节数
- 写入的兆字节数。
网络(Infiniband 数据)
AcctGatherInterconnectType=acct_gather_interconnect/ofed
在 slurm.conf 中是收集任务数据所必需的。 适当地在 slurm.conf 中的 JobAcctGatherFrequency 或命令行中的 --acctg-freq 中设置 network=freq。
网络时间序列中的每个数据样本包含以下数据项。
- 日期时间
- 数据样本采集时的时间。这可以用于将活动与其他来源(如日志)关联起来。
- 时间
- 自步骤开始以来的经过时间。
- 进入的数据包
- 进入的数据包数量。
- 读取的兆字节数
- 通过接口进入的兆字节数。
- 出去的数据包
- 出去的数据包数量。
- 写入的兆字节数
- 通过接口出去的兆字节数。
任务数据
JobAcctGatherType=jobacct_gather/linux
在 slurm.conf 中是收集任务数据所必需的。 适当地在 slurm.conf 中的 JobAcctGatherFrequency 或命令行中的 --acctg-freq 中设置 task=freq。
任务时间序列中的每个数据样本包含以下数据项。
- 日期时间
- 数据样本采集时的时间。这可以用于将活动与其他来源(如日志)关联起来。
- 时间
- 自步骤开始以来的经过时间。
- CPU 频率
- 采样时的 CPU 频率。
- CPU 时间
- 在采样期间使用的 CPU 时间(以秒为单位)。
- CPU 利用率
- 在该时间段内的 CPU 利用率。
- RSS
- 采样时的 RSS 值。
- 虚拟内存大小
- 采样时的虚拟内存大小值。
- 页面
- 样本中使用的页面。
- 读取的兆字节数
- 从本地磁盘读取的兆字节数。
- 写入的兆字节数
- 写入到本地磁盘的兆字节数。
最后修改日期 2022 年 10 月 17 日