控制组 v2 插件
目录
- 概述
- 从 cgroup v1 转换
- 遵循 cgroup v2 规则
- 遵循 systemd 规则
- cgroup/v2 概述
- 层次结构概述
- 在任务级别工作
- 基于 eBPF 的设备控制器
- 运行不同节点的不同 cgroup 版本
- 配置
- 要求
- 在 cgroup v2 上的 PAM Slurm Adopt 插件
- 限制
概述
Slurm 提供对具有控制组 v2 的系统的支持。
有关此 cgroup 版本的文档可以在 kernel.org 找到
控制组 v2 文档。
cgroup/v2 插件是 Slurm 的内部 API,由其他插件使用, 如 proctrack/cgroup、task/cgroup 和 jobacctgather/cgroup。本文档概述了它的设计,旨在更好地了解 当 Slurm 使用此插件限制资源时系统上发生的情况。
在阅读本文档之前,我们假设您已经阅读了 cgroup v2 内核 文档,并且您对大多数概念和术语都很熟悉。 阅读 systemd 的 控制组接口文档同样重要,因为 cgroup/v2 需要 与 systemd 进行交互,许多概念会重叠。最后,建议您了解 eBPF 技术的概念,因为在 cgroup v2 中,设备 cgroup 控制器是基于 eBPF 的。
从 cgroup v1 转换
现有的 Slurm 安装可能正在使用 Slurm 的 cgroup/v1 插件。 希望使用 cgroup/v2 新功能的站点可以将其节点转换为运行 cgroup v2, 前提是操作系统支持。Slurm 支持运行混合 cgroup/v1 和 cgroup/v2 插件的计算节点。
重新配置 Systemd
在某些情况下,可能需要对 systemd 配置进行一些更改以支持 cgroup v2。 如果满足以下任一条件,则需要完成本节中的程序:
- Systemd 版本小于 252
- 文件
/proc/1/cgroup包含多行或第一行以非零值开头。例如:- 需要重新配置 Systemd:
12:cpuset:/ 11:hugetlb:/ 10:perf_event:/ . . .
- 准备好使用 cgroup v2(跳到
下一节):
0::/init.scope
- 需要重新配置 Systemd:
以下程序将重新配置此类系统以支持 cgroup v2:
- 交换 kernel 命令行选项以支持 systemd 的 cgroup v2:
systemd.unified_cgroup_hierarchy=1 systemd.legacy_systemd_cgroup_controller=0 cgroup_no_v1=all
对于 Debian 系统的示例命令:sed -e 's@^GRUB_CMDLINE_LINUX=@#GRUB_CMDLINE_LINUX=@' -i /etc/default/grub echo 'GRUB_CMDLINE_LINUX="systemd.unified_cgroup_hierarchy=1 systemd.legacy_systemd_cgroup_controller=0 cgroup_no_v1=all"' >> /etc/default/grub update-grub
对于 Red Hat 系统的示例命令:grubby --update-kernel=ALL --args="systemd.unified_cgroup_hierarchy=1 systemd.legacy_systemd_cgroup_controller=0 cgroup_no_v1=all"
- 重启以应用新的内核命令行选项。
- 验证内核是否具有正确的命令行选项:
grep -o -e systemd.unified_cgroup_hierarchy=. -e systemd.legacy_systemd_cgroup_controller=. /proc/cmdline systemd.unified_cgroup_hierarchy=1 systemd.legacy_systemd_cgroup_controller=0
如果输出不完全匹配,则重复之前的步骤并验证内核是否给出了正确的命令行选项。 - 验证没有任何 cgroup v1
控制器挂载,并且
您的系统没有以混合模式运行
混合模式的示例:$ grep -v ^0: /proc/self/cgroup 8:net_cls,net_prio:/ 6:name=systemd:/
如果有任何条目,则需要重启。如果重启后仍有条目,则有一个进程正在主动挂载 Cgroup v1 挂载,需要停止。
一般转换
从 cgroup v1 切换到 v2 时需要执行以下程序:
- 修改 Slurm 配置以允许 cgroup/v2 插件:
/etc/slurm/cgroup.conf:- 删除以:
CgroupAutomount=
开头的行 - 删除以:
CgroupMountpoint=
开头的行 - 如果存在,删除行:
CgroupPlugin=cgroup/v1
- 添加行:
CgroupPlugin=autodetect
- 删除以:
- 根据正常启动程序重启 Slurm 守护进程
遵循 cgroup v2 规则
内核的控制组 v2 有两个特殊性,影响 Slurm 需要如何构建其内部 cgroup 树。
自上而下的约束
资源是自上而下分配到树中的,因此控制器仅在 cgroup 目录中可用, 如果父节点在其 cgroup.controllers 文件中列出了它并添加到其 cgroup.subtree_control 中。 此外,如果一个或多个子节点启用了控制器,则无法禁用子树中激活的控制器。对于 Slurm,这意味着我们需要通过修改 cgroup.subtree_control 并为子节点启用所需的控制器来管理我们的层次结构。
无内部进程约束
除了根 cgroup 之外,父 cgroups(真正称为域 cgroups)只能为其子节点启用控制器, 如果它们自己级别没有任何进程。这意味着我们可以在 cgroup 目录中创建子树, 但是在写入 cgroup.subtree_control 之前,父节点的 cgroup.procs 中列出的所有 pid 必须迁移到子节点。 这要求所有进程必须位于树的叶子上,因此不可能在非叶子目录中有 pid。
遵循 systemd 规则
Systemd 目前是使用最广泛的初始化机制。因此,Slurm 需要找到与 systemd 规则共存的方法。 systemd 的设计者提出了一条新规则,称为“单一写入者”规则,这意味着每个 cgroup 只有一个所有者,其他人不应对其进行写入。 有关此内容的更多信息,请参阅 systemd.io 控制组委托文档。在实践中,这意味着在内核启动时启动的 systemd 守护进程并占用 pid 1,将视自己为整个 cgroup 树的绝对所有者和唯一写入者。 这意味着 systemd 期望没有其他进程直接修改任何 cgroup,也不应有其他进程创建目录或移动 pid,而不让 systemd 知道。
有一种方法可以让 Slurm 无问题地工作,即在带有特殊 systemd 选项 Delegate=yes 的 systemd Unit 中启动 Slurm 守护进程。 在 systemd 单元中启动 slurmd,将为 Slurm 提供一个“委托”的 cgroup 子树,在文件系统中可以创建目录、移动 pid 并管理自己的层次结构。 实际上,发生的情况是 systemd 在其内部数据库中注册一个新的 Unit 并将 cgroup 目录与其关联。 然后,对于 cgroup 树的任何未来“侵入性”操作,systemd 将有效地忽略“委托”目录。
这与 cgroup v1 中发生的情况类似,因为这不是内核规则,而是 systemd 规则。 但是,这一事实与新的 cgroup v2 规则结合在一起,迫使 Slurm 选择一种与两者共存的设计。
真正的问题:systemd + 重启 slurmd
在为 Slurm 设计 cgroup/v2 插件时,最初的想法是让 slurmd 在其自己的根 cgroup 目录中设置所需的层次结构。 它将为自己创建一个特定的目录,然后将作业和步骤放置在其他相应的目录中。这将保证 无内部进程约束 规则。
这在我们需要重启 slurmd 之前运作良好。由于整个层次结构已经从 slurmd cgroup 开始创建, 重启 slurmd 将终止 slurmd 进程,然后启动一个新的进程,该进程将被放入原始组树的根部。 由于该目录现在被称为“域控制器”(它包含子目录),而不再是叶子,因此 无内部进程约束 规则将被打破,systemd 将无法启动守护进程。
由于 systemd 中缺乏处理这种情况的机制,我们别无选择,只能将 slurmd 和派生的 slurmstepds 分离到不同的子树目录中。 由于 systemd 关于在树上作为单一写入者的设计规则,无法仅从 slurmd 或 slurmstepd 本身执行“mkdir”, 然后将 stepd 进程移动到一个新的独立目录,这将意味着该目录不受 systemd 控制,并会导致问题。
实际上,在 systemd 中,有两种类型的 Units 可以获得“Delegate=yes”参数,并且与 cgroup 目录直接相关。 一种是“服务”,另一种是“范围”。我们对“范围”感兴趣:
- Systemd 范围: systemd 将 pid 作为参数,创建一个 cgroup 目录,然后将提供的 pid 添加到该目录中。该范围将保持,直到该 pid 消失。
值得注意的是,与主要 systemd 开发人员的讨论提出了 RemainAfterExit systemd 参数。 该参数旨在使单元在所有进程消失时仍然保持活动状态。此选项仅对“服务”有效,而不适用于“范围”。 如果它也适用于范围,这将是一个非常有趣的选项。他们表示,其功能可以扩展,不仅保持单元,还可以在单元手动终止之前保持 cgroup 目录。 目前,单元保持活动状态,但 cgroup 无论如何都会被清理。
在所有这些背景下,我们准备展示用于解决 slurmd 重启问题的解决方案。
- 在 slurmd 启动时创建一个新的范围以托管新的 slurmstepd 进程。 它在 第一次 slurmd 启动时进行一次调用。Slurmd 为未来的 slurmstepd pid 准备一个范围, 并且 stepd 本身在启动时将自己移动到那里。这不会带来任何性能问题,概念上就像是一个较慢的“mkdir” + 仅在第一次启动时通知 systemd。 将进程从一个委托单元移动到另一个委托单元得到了 systemd 开发人员的批准。唯一的缺点是该范围需要进程,否则将终止并清理 cgroup, 因此 slurmd 需要创建一个“sleep”无限进程,我们将其编码为“slurmstepd infinity”进程,该进程将在范围内永远存在。 将来,如果 RemainAfterExit 参数扩展到范围并允许 cgroup 树不被销毁,则不再需要此无限进程。
最后,我们最终将 slurmd 与 slurmstepds 分离,使用带有“Delegate=yes”选项的范围。
不遵循 systemd 规则的后果
已知存在一个问题,即 systemd 可能决定清理 cgroup 层次结构,目的是使其与其内部数据库匹配。 例如,如果系统中没有带有“Delegate=yes”的单元, 它将遍历树并可能停用所有它认为未使用的控制器。在我们的测试中,我们停止了所有带有 “Delegate=yes”的单元,发出了“systemd reload”或“systemd reset-failed”,并目睹了 cpuset 控制器 从我们“手动”创建的 cgroup 树深处消失。 还有其他情况,systemd 开发人员和文档声称他们是树的唯一单一写入者,这使得 SchedMD 决定保持安全, 让 Slurm 与 systemd 共存。
值得注意的是,我们添加了 IgnoreSystemd 和 IgnoreSystemdOnFailure 作为 cgroup.conf 参数,这将避免与 systemd 的任何接触, 并将仅使用常规“mkdir”来创建相同的目录结构。这些参数仅用于开发和测试目的。
没有 systemd 的 Linux 发行版会发生什么?
Slurm 不支持它们,但它们仍然可以工作。唯一的要求是在系统中安装 libdbus、ebpf 和 systemd 软件包以编译 slurm。 然后,您可以在 cgroup.conf 中设置 IgnoreSystemd 参数以手动创建 /sys/fs/cgroup/system.slice/ 目录。 满足这些要求后,Slurm 应该正常工作。
cgroup/v2 概述
我们将简要解释此插件的工作流程。
slurmd 启动
新系统:slurmd 启动。一些使用 cgroup 的插件(proctrack、jobacctgather 或 task)调用 cgroup/v2 插件的 init() 函数。立即发生的事情是 slurmd 使用 libdbus 调用 dbus,并创建一个新的 systemd “范围”。 范围名称是预定义的,并根据内部常量 SYSTEM_CGSCOPE 在 SYSTEM_CGSLICE 下设置。最终名称为“slurmstepd.scope”或“nodename_slurmstepd.scope”,具体取决于 Slurm 是否使用 --enable-multiple-slurmd 编译(前缀节点名称)或否。与此范围关联的 cgroup 目录将固定为: “/sys/fs/cgroup/system.slice/slurmstepd.scope”或 “/sys/fs/cgroup/system.slice/nodename_slurmstepd.scope”。
由于对 dbus “startTransientUnit”的调用需要 pid 作为参数, slurmd 需要派生一个“slurmstepd infinity”并将此参数用作参数。
对 dbus 的调用是异步的,因此 slurmd 将消息发送到 Dbus 总线,然后开始主动等待,等待范围目录出现。 如果目录在硬编码的超时内未出现,则失败。 否则,它将继续,slurmd 然后在最近创建的范围目录中为新的 slurmstepds 和无限 pid 创建一个目录,称为“system”。 它将无限进程移动到那里,然后在新的 cgroup 目录中启用所有所需的控制器。
由于这是一个常规的 systemd 单元,范围将显示在 “systemctl list-unit-files”和其他 systemd 命令中,例如:
]$ systemctl cat gamba1_slurmstepd.scope
# /run/systemd/transient/gamba1_slurmstepd.scope
# 这是一个瞬态单元文件,通过 systemd API 程序化创建。请勿编辑。
[Scope]
Delegate=yes
TasksMax=infinity
]$ systemctl list-unit-files gamba1_slurmstepd.scope
UNIT FILE STATE VENDOR PRESET
gamba1_slurmstepd.scope transient -
1 unit files listed.
]$ systemctl status gamba1_slurmstepd.scope
● gamba1_slurmstepd.scope
Loaded: loaded (/run/systemd/transient/gamba1_slurmstepd.scope; transient)
Transient: yes
Active: active (abandoned) since Wed 2022-04-06 14:17:46 CEST; 2h 47min ago
Tasks: 1
Memory: 1.6M
CPU: 258ms
CGroup: /system.slice/gamba1_slurmstepd.scope
└─system
└─113094 /home/lipi/slurm/master/inst/sbin/slurmstepd infinity
apr 06 14:17:46 llit systemd[1]: Started gamba1_slurmstepd.scope.
slurmd 初始化的另一个操作将是检测系统中可用的控制器(在 /sys/fs/cgroup 中),并递归启用所需的控制器,直到达到其级别。 它将为最近创建的 slurmstepd 范围启用它们。
]$ cat /sys/fs/cgroup/system.slice/gamba1_slurmstepd.scope/cgroup.controllers cpuset cpu io memory pids ]$ cat /sys/fs/cgroup/system.slice/gamba1_slurmstepd.scope/cgroup.subtree_control cpuset cpu memory
如果启用了资源专业化,slurmd 还将在其自己的级别设置内存和/或 cpu 约束。
slurmd 重启
Slurmd 像往常一样重启。当重启时,它将检测“范围”目录是否已存在,如果存在则不执行任何操作。 否则,它将尝试再次设置范围。
slurmstepd 启动
当需要创建新步骤时,无论是作为新作业的一部分还是作为现有作业的一部分,slurmd 将在其自己的 cgroup 目录中派生 slurmstepd 进程。 slurmstepd 将立即开始初始化,并且(如果启用了 cgroup 插件)将推断范围目录并将自己移动到“等待”区域,即 /sys/fs/cgroup/system.slice/slurmstepd_nodename.scope/system 目录。 它将立即初始化作业和步骤 cgroup 目录,并将自己移动到其中,按需设置 subtree_controllers。
终止和清理
当作业结束时,slurmstepd 将负责删除所有创建的目录。slurmstepd.scope 目录将 永远 不会被 Slurm 删除或停止, 而“slurmstepd infinity”进程将永远不会被 Slurm 杀死。
当 slurmd 结束时(由于在支持的系统上是由 systemd 启动的),其 cgroup 将仅由 systemd 清理。
特殊情况 - 手动启动
从 systemd 启动 slurmd 会创建 slurmd 单元及其自己的 cgroup。 然后 slurmd 启动 slurmstepd.scope,后者又创建一个新的 cgroup 树。 为作业生成的任何新进程都迁移到此范围内。如果,而不是从 systemd 启动 slurmd,而是从命令行手动启动 slurmd, 情况就不同了。slurmd 将被派生到相同终端的 cgroup 中,并将与终端进程本身(以及可能与其他用户进程)共享 cgroup 树。
slurmd 通过读取 INVOCATION_ID 环境变量来检测这种情况。该变量通常由 systemd 在启动进程时设置,是确定 slurmd 是否在其自己的 cgroup 中启动或手动启动到共享 cgroup 的方法。 在第一种情况下,slurmd 不会尝试移动到任何其他 cgroup。在第二种情况下,如果 INVOCATION_ID 未设置,它将尝试移动到 slurmstepd.scope cgroup 内的一个新子目录。
当您的环境中设置了 INVOCATION_ID 并且您尝试手动启动 slurmd 时,会出现问题。slurmd 将认为它在自己的 cgroup 中, 并且不会尝试迁移自己,如果设置了 MemSpecLimit 或 CoreSpecLimit,slurmd 将在此 cgroup 中应用内存或核心限制,间接限制您的终端或其他进程。 例如,在终端中以低内存启动 slurmd,设置 MemSpecLimit,将其发送到后台,然后尝试运行任何消耗内存的程序,可能会导致您的进程被 OOM 杀死。
为了避免这种情况,我们建议您在启动 Slurm 之前取消设置 INVOCATION_ID,在设置此环境变量的情况下。
与此相关的另一个问题是,当您的终端的 cgroup 中未启用所有控制器时,这通常发生在 systemd 的 user.slice 中。 然后 slurmd 将无法初始化,因为它无法检测到所需的控制器,并将显示类似于以下内容的错误:
]# slurmd -Dv slurmd: error: 控制器 cpuset 未启用! slurmd: error: 控制器 cpu 未启用! ... slurmd: slurmd 版本 23.11.0-0rc1 启动 slurmd: error: cpu cgroup 控制器不可用。 slurmd: error: 初始化内存或 cpu 控制器时出现问题 slurmd: error: 无法为 jobacct_gather/cgroup 创建指定插件名称的上下文:插件 init() 回调失败 slurmd: fatal: 无法初始化 jobacct_gather
一种解决方法是在 cgroup.conf 中设置 EnableControllers=yes,但请注意,这不会保护您免受其他进程可能出现的 OOM 错误,如前所述。 此外,这将从根 /sys/fs/cgroup 修改整个 cgroup 树。因此,真正的解决方案是通过单元文件启动 slurmd,或取消设置 INVOCATION_ID 环境变量。
注意:请注意,这不仅在手动启动 slurmd 时发生。如果您使用自定义脚本启动 slurmd,即使脚本是通过 systemd 运行的,也可能发生这种情况。 我们鼓励您使用我们提供的 slurmd.service 文件,或至少在您的启动脚本中显式取消设置 INVOCATION_ID。
故障排除启动
由于与 systemd 的集成具有一定的复杂性,并且由于不同的配置或操作系统设置的变化,我们鼓励您在 slurm.conf 中设置调试标志,以便在 slurm 未在 cgroup/v2 中启动时诊断发生了什么:
DebugFlags=cgroup SlurmdDebug=debug
如果 slurmd 启动但抛出 cgroup 错误,建议查看 slurmd 启动的 cgroup。例如,这显示 slurmd 在用户切片 cgroup 中启动,这通常是错误的,并且可能是从设置了 INVOCATION_ID 的终端手动启动的:
[root@llagosti ~]# cat /proc/$(pidof slurmd)/cgroup 0::/user.slice/user-1000.slice/user@1000.service/app.slice/app-gnome-tmaster-47247.scope [root@llagosti ~]# grep -i INVOCATION_ID= /proc/47279/environ grep: /proc/47279/environ: binary file matches
相反,当 slurmd 被手动且正确地启动时:
[root@llagosti ~]# cat /proc/$(pidof slurmd)/cgroup 0::/system.slice/gamba1_slurmstepd.scope/slurmd
最后,如果 slurmd 是由 systemd 启动的,您应该看到它生活在自己的 cgroup 中:
[root@llagosti ~]# cat /proc/$(pidof slurmd)/cgroup 0::/system.slice/slurmd.service
层次结构概述
层次结构将呈现以下形式: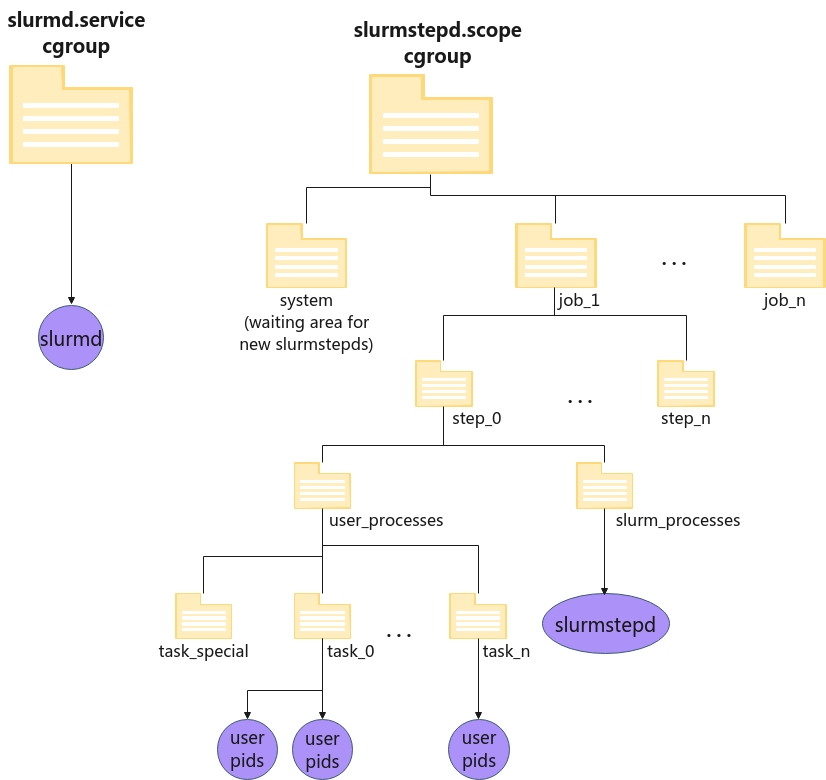
图 1. Slurm cgroup v2 层次结构。
左侧是 slurmd 服务,由 systemd 启动并独自生活在其委托的 cgroup 中。
右侧是 slurmstepd 范围,cgroup 树中的一个目录,也被委托,所有 slurmstepd 和用户作业将驻留在其中。slurmstepd 最初迁移到等待新 stepds 的区域,即 system 目录,并且立即在初始化作业层次结构时将自己移动到相应的 job_x/step_y/slurm_processes 目录。
用户进程将由 slurmstepd 生成并移动到适当的任务目录中。
此时,应该可以通过发出以下命令检查在 slurmstepd 范围内运行的进程:
]$ systemctl status slurmstepd.scope
● slurmstepd.scope
Loaded: loaded (/run/systemd/transient/slurmstepd.scope; transient)
Transient: yes
Active: active (abandoned) since Wed 2022-04-06 14:17:46 CEST; 2min 47s ago
Tasks: 24
Memory: 18.7M
CPU: 141ms
CGroup: /system.slice/slurmstepd.scope
├─job_3385
│ ├─step_0
│ │ ├─slurm
│ │ │ └─113630 slurmstepd: [3385.0]
│ │ └─user
│ │ └─task_0
│ │ └─113635 /usr/bin/sleep 123
│ ├─step_extern
│ │ ├─slurm
│ │ │ └─113565 slurmstepd: [3385.extern]
│ │ └─user
│ │ └─task_0
│ │ └─113569 sleep 100000000
│ └─step_interactive
│ ├─slurm
│ │ └─113584 slurmstepd: [3385.interactive]
│ └─user
│ └─task_0
│ ├─113590 /bin/bash
│ ├─113620 srun sleep 123
│ └─113623 srun sleep 123
└─system
└─113094 /home/lipi/slurm/master/inst/sbin/slurmstepd infinity
注意:如果在开发系统上运行并使用 --enable-multiple-slurmd,则 slurmstepd.scope 将在其前面加上节点名称。
在任务级别工作
在用户作业层次结构中有一个名为 task_special 的目录。 jobacctgather/cgroup 和 task/cgroup 插件分别在任务级别获取统计信息和限制资源。其他插件如 proctrack/cgroup 仅在步骤级别工作。为了统一层次结构并使其适用于所有不同的插件,当一个插件请求将 pid 添加到步骤但不添加到任务时, pid 将放入一个名为 task_special 的特殊目录。如果另一个插件将此 pid 添加到任务,它将从那里迁移。通常,这发生在 proctrack 插件调用 proctrack_g_add_pid 时。
基于 eBPF 的设备控制器
在控制组 v2 中,设备控制器接口已被移除。 现在需要创建一个类型为 BPF_PROG_TYPE_CGROUP_DEVICE 的 bpf 程序并将其附加到所需的 cgroup。 此程序由 slurmstepd 动态创建并通过 bpf 系统调用插入内核,描述哪些设备被允许或拒绝用于作业、步骤和任务。
唯一管理的设备是 gres.conf 文件中描述的设备。
此类程序的插入和移除将记录在系统日志中:
apr 06 17:20:14 node1 audit: BPF prog-id=564 op=LOAD apr 06 17:20:14 node1 audit: BPF prog-id=565 op=LOAD apr 06 17:20:14 node1 audit: BPF prog-id=566 op=LOAD apr 06 17:20:14 node1 audit: BPF prog-id=567 op=LOAD apr 06 17:20:14 node1 audit: BPF prog-id=564 op=UNLOAD apr 06 17:20:14 node1 audit: BPF prog-id=567 op=UNLOAD apr 06 17:20:14 node1 audit: BPF prog-id=566 op=UNLOAD apr 06 17:20:14 node1 audit: BPF prog-id=565 op=UNLOAD
运行不同节点的不同 cgroup 版本
要使用的 cgroup 版本完全取决于节点。因此,可以在不同节点上运行相同的作业,使用不同的 cgroup 插件。 配置是在 cgroup.conf 中按节点进行的。
无法在不重启和配置节点的情况下在 cgroup.conf 中交换 cgroup 插件的版本。 由于我们不支持混合控制器版本的“混合”系统,因此节点必须使用一个特定的 cgroup 版本启动。
配置
在配置方面,设置与以前的 cgroup/v1 插件没有太大区别,但在配置 cgroup 插件时必须考虑以下事项:
Cgroup 插件
此选项允许系统管理员指定将在节点上运行的 cgroup 版本。建议使用 autodetect 并忘记它,但也可以强制使用插件版本。
CgroupPlugin=[autodetect|cgroup/v1|cgroup/v2]
开发者选项
- IgnoreSystemd=[yes|no]:此选项用于避免任何调用 dbus 以联系 systemd。slurmd 启动时,它将仅使用“mkdir”来准备 slurmstepds 的 cgroup 目录,而不是请求创建新的范围。 在生产系统中使用此选项与 systemd 不受支持,原因如上所述。 但是,对于没有 systemd 的系统,这个选项可能会很有用。
- IgnoreSystemdOnFailure=[yes|no]:此选项将在创建 cgroup 目录时回退到手动模式,而不创建 systemd “范围”。 仅当对 dbus 的调用返回错误时,才会这样做,就像使用 IgnoreSystemd 一样。
- EnableControllers=[yes|no]:设置后,slurmd 将检查 /sys/fs/cgroup/cgroup.controllers 中所有可用的控制器,并将它们递归启用在 cgroup.subtree_control 文件中,直到达到 slurmd 级别。这通常在 RHEL8/Rocky8、某些容器或 systemd < 244 时是必需的。
- CgroupMountPoint=/path/to/mount/point:在大多数情况下,使用 cgroup v2 时,不应使用此参数,因为 /sys/fs/cgroup 将是唯一的 cgroup 目录。
被忽略的参数
由于 Cgroup v2 不再在内存控制器中提供可交换性接口,因此 cgroup.conf 中的以下参数将被忽略:
MemorySwappiness=
要求
要构建 cgroup/v2,在配置时检查了两个必需的库。请查看您的 config.log,以查看它们是否在您的系统上正确检测到。
| 库 | 头文件 | 包提供 | 配置选项 | 目的 |
| eBPF | include/linux/bpf.h | kernel-headers (>= 5.7) | --with-bpf= | 限制设备到作业/步骤/任务 |
| dBus | dbus-1.0/dbus/dbus.h | dbus-devel (>= 1.11.16) | n/a | dBus API 用于联系 systemd |
注意:在没有 systemd 的系统中,这些库在编译 Slurm 时也需要。如果存在其他要求,例如不包括 dbus 或 systemd 包要求,则必须修改配置文件。
为了使用 cgroup/v2,需要有效的 cgroup 命名空间、挂载命名空间和进程命名空间,以及其各自的挂载。这通常适用于容器化环境, 根据配置,命名空间被创建,但相关的挂载点未挂载。这可能发生在 Docker 或 Kubernetes 的某些配置中。
Kubernetes 的默认行为已被测试并发现它使用与 Slurm 兼容的正确 cgroup 设置。至于 Docker,要么使用主机 cgroup 命名空间,要么通过使用 --cgroupns=private 创建一个私有命名空间。请注意,您需要 --privileged,否则容器将没有对 cgroup 的写权限。 要使用主机 cgroup 命名空间,请确保容器在子 cgroup 内创建,您可以使用 --cgroupns=host 选项指定此操作模式,并使用 --cgroup-parent 指定容器的父 cgroup。
在 cgroup v2 上的 PAM Slurm Adopt 插件
pam_slurm_adopt 插件 与 cgroup/v1 的 API 有依赖关系,因为在某些情况下它依赖于作业的 cgroup 创建时间来选择哪个作业 ID 应该被选中以将您的 sshd pid 添加到。 在 v2 中,我们希望消除这种依赖关系,而不依赖于 cgroup 文件系统,而是简单地依赖于作业 ID。这不会保证 sshd 会话被插入到最新的作业中,但会保证它将放入最大的作业 ID。 因此,我们消除了插件对特定 cgroup 层次结构的依赖。
限制
cgroup/v2 插件可以提供内核 cgroup 接口提供的所有 CPU 和内存的计量统计信息。这不包括虚拟内存,因此在使用 jobacct_gather/cgroup 与 cgroup/v2 结合时,期望 AveVMSize, MaxVMSize, MaxVMSizeNode, MaxVMSizeTask 和 vmem 等指标的值为 0。
关于真实堆栈大小 (RSS),此插件提供 cgroup 的 memory.current 值,该值不等于 procfs 提供的 RSS 值。 然而,它是内核在其 OOM 杀手逻辑中使用的相同值。
RHEL8 / Rocky8: 根据其发布说明,cgroups v2的支持始于RHEL8.0的技术预览,并且这些特性已回溯到4.18内核。在RHEL8.2中,说明指出cgroups v2已完全支持,但他们发出警告,表示并非所有特性都已实现。我们建议联系红帽公司以获取他们对cgroups v2支持的状态,该状态应在他们的工单中跟踪:BZ#1401552。此版本还附带systemd 239,该版本不支持cpuset接口。Systemd < 244: 在此版本之前,systemd不支持cpuset控制器,并且在旧内核中,cpu控制器默认未启用。可以通过在system.conf中设置
DefaultCpuAccounting=yes来启用cpu控制器。对于cpuset控制器,您需要在cgroup.conf中设置
EnableControllers=yes。
最后修改于2024年10月11日